

AI Solutions for Always-Optimized Operations
Agentune: From Simulated Customers to Data-Driven, Self-Improving Agents

Agentune: From Simulated Customers to Data-Driven, Self-Improving Agents
After months of work, we’re excited to release Agentune Analyze & Improve v1.0 – the next major milestone in autonomous, performance-driven agent engineering
If you’ve shipped a real customer-facing agent, you’ve probably hit the same wall as everyone else:
- You have transcripts, KPIs, and anecdotes… but no reliable way to know what actually moves your metrics.
- You tweak prompts, swap models, add tools – but it’s mostly guesswork.
- You test and learn on real customers but that’s risky, slow and expensive.
Agentune is the open-source answer to this: an engine for the Analyze → Improve → Evaluate loop of agent performance optimization.
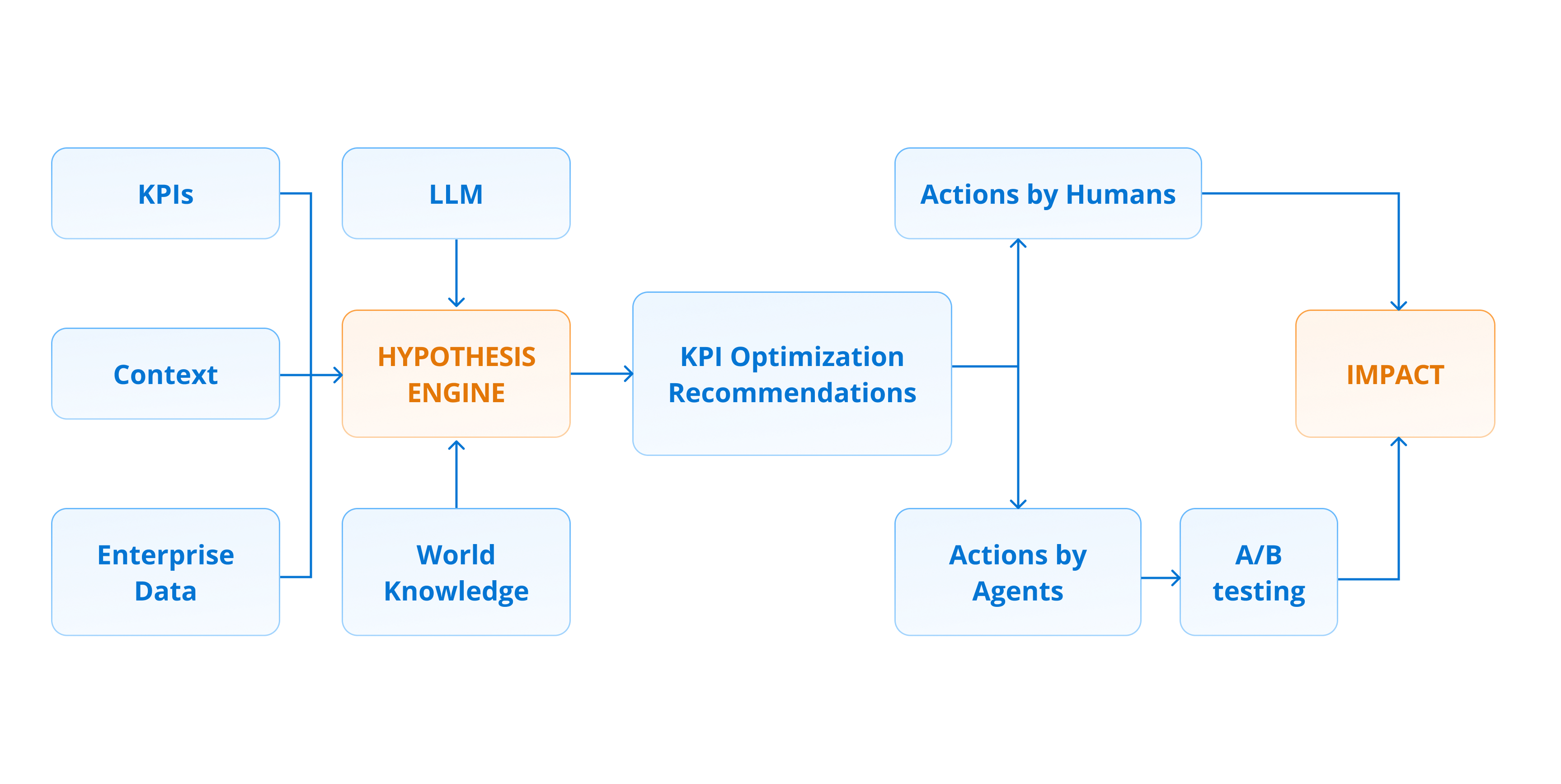
Agentune Analyze will produce recommendations for agent improvements (prompt, workflows, additional data, tools) like:
Example outputs
Enterprise Sales Agent
Insert timeline probe if not mentioned by minute 3
Recommendation: If the user hasn’t mentioned their decision timeline by minute three, insert a gentle timeline probe.
Finding: Deals with early timeline qualification show 2× higher conversion rates.
Evidence example: In several unsuccessful calls, the rep waits until the final minute to ask about timing, discovering too late that the buyer was not ready to purchase this quarter.
End calls with a clear next step or calendar commitment
Recommendation: End the call with a clear next step or calendar commitment.
Finding: While 50% of successful calls include a scheduled follow-up, only 8% of unsuccessful calls do.
Evidence example: In several conversations, the agent promises to “send an email” but fails to confirm a specific date/time, and the customer ends the call without agreeing to any follow-up.
Customer-Support Agent
Clarification when partial account info + urgency
Recommendation: Insert a clarification step when the user provides partial account information but expresses urgency.
Finding: Calls with incomplete account details plus urgency lead to repeated back-and-forth in 30% of the cases and 45% longer handle times.
Evidence example: In several conversations, users provide only their first name and last four digits, say “this is urgent,” and the agent attempts troubleshooting before verifying full account identity, causing delays.
Banking Customer-Service Agent
Confirmation when the user contradicts themselves
Recommendation: Trigger a confirmation step when the user gives contradictory details (e.g., mismatched dates or amounts).
Finding: In 30% of conversations with contradictions, unresolved confusion leads to compliance-risk notes or follow-up calls.
Evidence example: In multiple calls, customers state two different withdrawal amounts, and the agent proceeds without clarification, resulting in incorrect case filings.
Several months ago we released Agentune-Simulate, a customer - agent conversation simulator that lets you test agents offline, generate data and evaluate outcomes of the conversations (e.g. sales conversion). Now we’re expanding that into a full optimization stack with:
- agentune-analyze – mines agent-customer conversations to uncover Agent KPI drivers (what drives the success of the agent in its task?).
- agentune-improve - produces recommendations for agent performance improvement informed by the outputs of agentune-analyze.
The next release will go further: connecting the dots between conversations and structured data (CRM, ERP, product catalog, etc.), to further contextualize the insights and ground them in enterprise data.
Recap: Agentune-Simulate – Don’t Learn on Live Customers
Before talking about analysis and improvement, it’s worth recapping what’s already there.
Agentune-Simulate lets you build a “twin” customer simulator from real conversations. It learns the distributions of intents, phrasing and flows, and then uses that to simulate new conversations against your agent – before you go live.
Typical workflow:
- Collect real conversations between customers and your (human or AI) agent.
- Train a customer simulator on those transcripts.
- Connect your agent (a LangChain/LangGraph/custom agent that exposes a chat interface).
- Simulate conversations at scale and track outcomes (CSAT, resolution, conversion, etc.).
- Use those simulations as the Evaluate step in your optimization loop.
At a code level, it looks roughly like this (from the PyPI quickstart):
pip install agentune-simulatefrom agentune.simulate import SimulationSessionBuilder
from langchain_openai import ChatOpenAI
# 1. Prepare or load your outcomes and vector store
outcomes = ... # outcome labels per conversation / scenario
vector_store = ... # semantic index over your real conversations
# 2. Build a simulation session
session = SimulationSessionBuilder(
default_chat_model=ChatOpenAI(model="gpt-4o"),
outcomes=outcomes,
vector_store=vector_store,
).build()
# 3. Run simulations against your agent
results = await session.run_simulation(real_conversations=conversations)With just that, you can:
- Stress-test a new agent version on realistic edge cases.
- Compare versions on real-ish workloads without burning real customers.
- Validate that changes from Agentune-Analyze / Improve actually help before rollout.
This was the first release: a solid Evaluate layer.
What’s New: Agentune Analyze & Improve
The new package agentune-analyze fills in the Analyze → Improve part of the loop.
At a high level, it:
- Ingests your conversations + KPI outcomes (and soon: structured context).
- Generates features capturing semantic, structural, and behavioral patterns in those conversations.
- Selects drivers that truly correlate with KPI shifts.
- Emits recommendations: concrete ways to change prompts, policies, flows or tooling to improve the agent.
It’s designed to “turn real conversations into insights that measurably improve your AI agents” by replacing intuition-driven tuning with evidence-driven decisions.
Why this matters
Before a tool like this, you likely had:
- A BI dashboard with aggregated KPIs (CSAT by queue, conversion by campaign, etc.).
- A handful of cherry-picked transcripts people screenshot in Slack.
- A lot of hand-wavey explanations of “why things dipped last week”.
But you didn’t have:
- A systematic way to say: “These patterns in conversations are driving KPI X up/down, with this effect size, and here’s what to change.”
- A way to triage thousands of improvement hypotheses down to a ranked short-list with evidence.
- A way to link recommendations back to specific conversations (so you can debug and trust them).
Agentune Analyze & Improve is explicitly built to do that.
How Agentune Analyze & Improve Works
You provide:
- Conversation data: transcripts for customer–agent dialogues (AI or human).
- Outcome / KPI labels: one or more target columns, e.g.
- csat_score
- resolved (0/1)
- conversion_outcome ∈ {win, undecided, lost}
- csat_score
- (Upcoming) Context data: structured CRM/product/policy features per conversation – this is where “connecting to structured data” kicks in.
Step 1 – Analyze
Agentune:
- Ingests conversations, outcomes, and optional context.
- Builds semantic features (intents, topics, patterns of phrasing, entities, etc.).
- Builds structural & behavioral features (turn counts, escalation patterns, latency, back-and-forth structure, etc.).
- Runs feature selection to find signals statistically correlated with your KPI(s).
Output: a set of interpretable drivers, each with:
- A human-readable description (“late discounts after shipping complaints lower CSAT”).
- Effect size / direction on KPI.
- Support / coverage.
- Representative examples.
Step 2 – Improve
Given those drivers, the Improve component:
- Maps them into concrete recommendations, such as:
- “Add a playbook step when the user mentions competitor X before price.”
- “Change escalation policy when shipping delays + refund requests co-occur.”
- “Adjust prompt section about warranties; it currently contradicts policy Y.”
- “Add a playbook step when the user mentions competitor X before price.”
- Ranks recommendations by expected impact on KPI and confidence.
- Links each recommendation back to supporting drivers and examples.
Those recommendations then flow naturally into:
- Prompt refactors
- Tool-calling / routing logic changes
- Policy or UX changes around the agent
- A new agent version you can validate with Agentune-Simulate
Getting Started with Agentune Analyze
End-to-End Simple Example
A minimal runnable example demonstrating the complete Agentune Analyze workflow: loading conversation data, running analysis, and generating action recommendations.
Prerequisites
pip install agentune-analyze
export OPENAI_API_KEY="your-api-key"Complete Code
import asyncio
import os
from pathlib import Path
from agentune.analyze.api.base import LlmCacheOnDisk, RunContext
from agentune.analyze.feature.problem import ProblemDescription
async def main() -> None:
data_dir = Path(__file__).parent / 'data'
# Define the problem
problem = ProblemDescription(
target_column='outcome',
problem_type='classification',
target_desired_outcome='process paused - customer needs to consider the offer',
name='Customer Service Conversation Outcome Prediction',
description='Analyze auto insurance conversations and suggest improvements',
target_description='The final outcome of the conversation'
)
# Create run context with LLM caching
async with await RunContext.create(
llm_cache=LlmCacheOnDisk(str(Path(__file__).parent / 'llm_cache.db'), 300_000_000)
) as ctx:
# Load data
conversations_table = await ctx.data.from_csv(
str(data_dir / 'conversations.csv')
).copy_to_table('conversations')
messages_table = await ctx.data.from_csv(
str(data_dir / 'messages.csv')
).copy_to_table('messages')
# Configure join strategy
join_strategy = messages_table.join_strategy.conversation(
name='messages',
main_table_key_col='conversation_id',
key_col='conversation_id',
timestamp_col='timestamp',
role_col='author',
content_col='message'
)
# Split data
split_data = await conversations_table.split(train_fraction=0.9)
# Run analysis
results = await ctx.ops.analyze(
problem_description=problem,
main_input=split_data,
secondary_tables=[messages_table],
join_strategies=[join_strategy]
)
# Generate recommendations
recommendations = await ctx.ops.recommend_actions(
analyze_input=split_data,
analyze_results=results,
recommender=ctx.defaults.conversation_action_recommender()
)
if __name__ == '__main__':
if 'OPENAI_API_KEY' not in os.environ:
raise ValueError('Please set OPENAI_API_KEY environment variable')
asyncio.run(main())Usage
Save the example above to a file, e2e_simple_example.py, and execute the file:
python e2e_simple_example.pyLearn More
- Getting Started Notebook - Interactive walkthrough with detailed explanations
- Advanced Examples - Customization and advanced workflows
- Data README - Documentation of the data used in examples
Visualize Results with Interactive Dashboards
Agentune Analyze includes utilities to generate interactive HTML dashboards for exploring your results. These are convenience tools to help visualize outputs so you can integrate them into your applications.
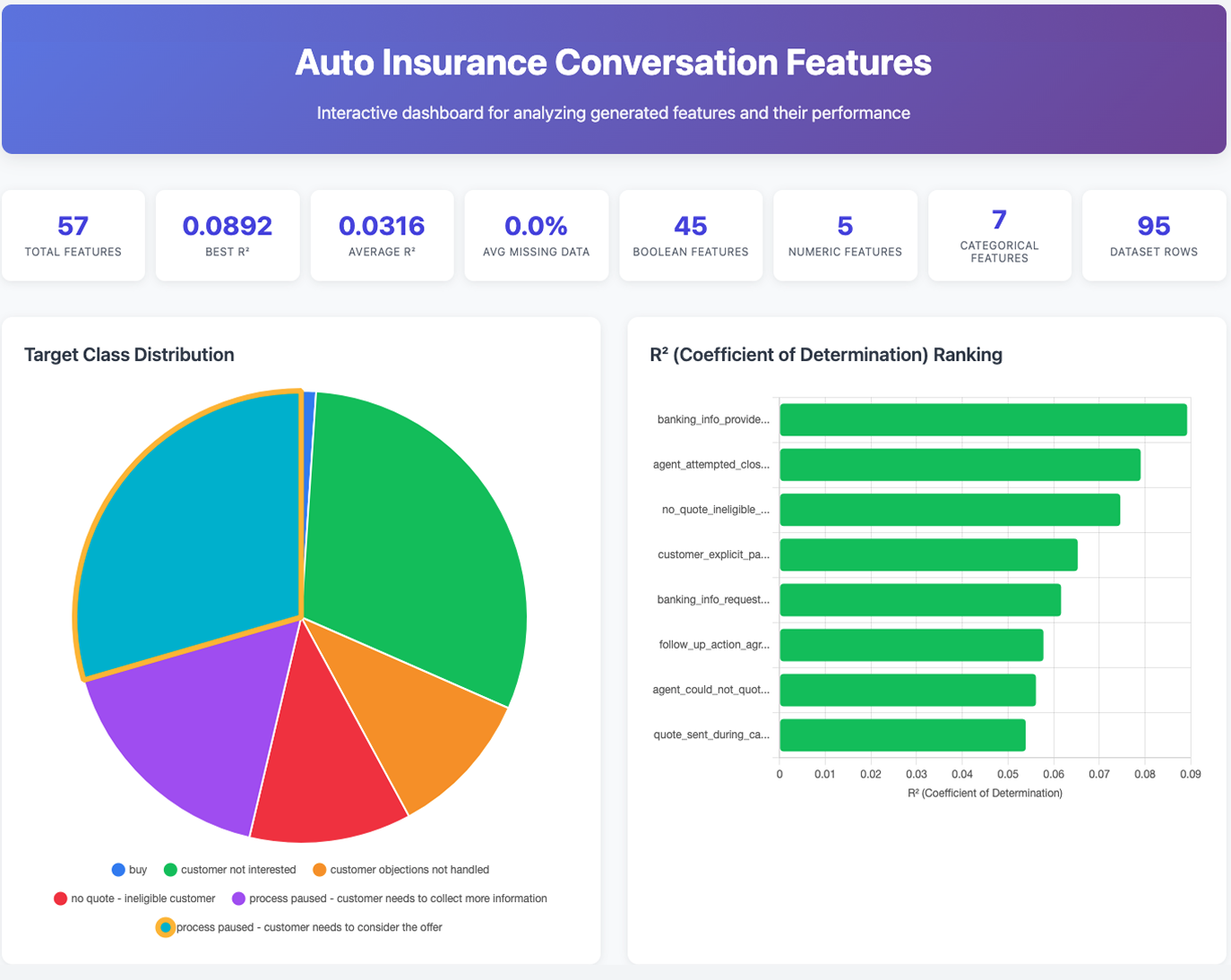
Analysis Dashboard
The interactive analysis dashboard includes:
- Target Distribution Chart: Visual breakdown of outcome classes (desired outcome highlighted with gold border)
- Feature Performance Ranking: Features sorted by R² (coefficient of determination)
- Sortable Feature Table: Detailed statistics for all features
- Interactive Feature Comparison Tool: Select multiple features to compare side-by-side
- Detailed Statistics: Click any feature row to expand and see:
- R² score (variance explained)
- Distribution statistics (mean, std, missing values, unique categories)
- Relationship statistics (lift matrix, class distributions)
- For numeric features: histogram visualization
Note: The R² (R-squared) metric shows what percentage of variance in the target outcome is explained by each feature. Values range from 0 (no predictive power) to 1 (perfect prediction). Higher values indicate stronger predictive features.
For examples of how to create dashboards, check out the Getting Started Notebook.
Example dashboard:
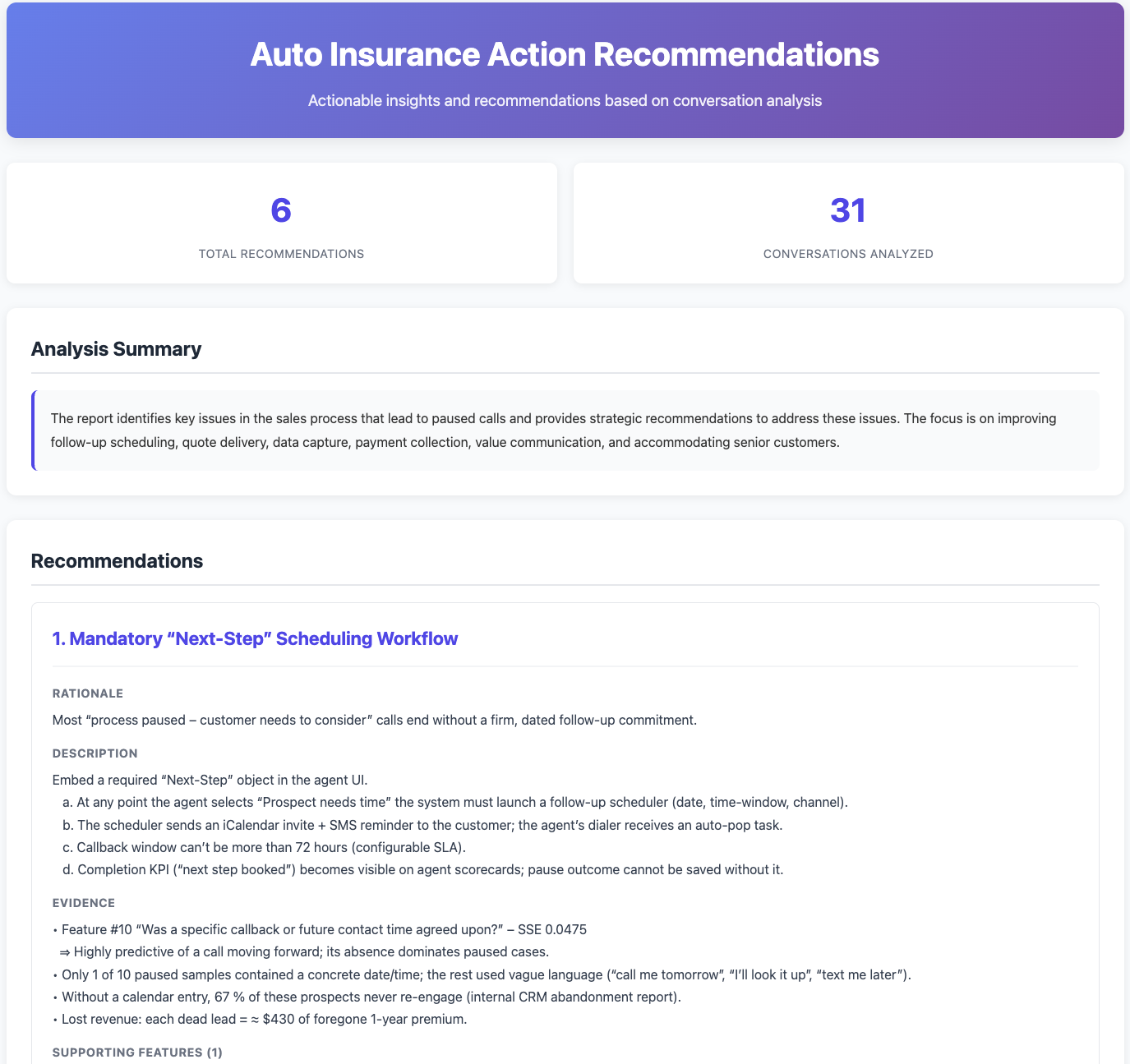
Recommendations Dashboard
The recommendations dashboard provides:
- Structured Recommendations: Each recommendation includes title, rationale, detailed description, and supporting evidence
- Evidence Links: Direct references to features and supporting conversations
- Implementation Details: Specific, actionable steps for each recommendation
Note: You can also access the full text report programmatically using recommendations.raw_report if needed for further processing.
Example dashboard:
Overview of the Agentune architecture
Library-nature
All Agentune code can be used as a python library. It has no dependencies other than Python packages, and makes no additional assumptions about the environment it runs in unless told to by user code. It doesn't require any external services or processes, and it doesn't run any sub-processes by default.
This is linked to two product requirements:
- Users can use parts of Agentune as a library, including on local development machines, and without installing anything other than a python package.
- All parts of Agentune can run anywhere a python library can; this lets us e.g. run on Spark and integrate with various Pythonic frameworks.
Design implications
- We are never opinionated. The user can tell us to do anything they want. We don't design our APIs or restrict our code to force or to forbid anything.
- We store data in files (local and remote) and not any kind of database that needs a standalone server.
- We scale horizontally, not vertically. Approximately speaking, to work with a huge dataset you need to figure out how to shard it.
- We never read or write files the user didn't explicitly ask us to, and prefer working with single files to assuming control of entire directories.
For detailed information on architecture and design principles, see the Architecture Guide.
How to Start Using Agentune in Your Stack
If you’re already running agents in production, here’s a concrete path:
- Start with your logs
- Export a few thousand conversations with outcomes.
- Normalize into per-turn + per-conversation tables.
- Export a few thousand conversations with outcomes.
- Run a first Analyze & Improve pass
- Install agentune-analyze.
- Walk through the 01_getting_started.ipynb notebook in the repo (for exact code).
- Inspect drivers and recommendations.
- Install agentune-analyze.
- Implement one or two high-impact recommendations
- Update prompts / flows / tooling.
- Tag that agent version clearly.
- Update prompts / flows / tooling.
- Validate in the lab
- Use agentune-simulate to simulate your typical workload.
- Compare KPIs vs baseline.
- Use agentune-simulate to simulate your typical workload.
- Ship and monitor
- Roll out with confidence that you’ve already stress-tested on realistic data.
- Feed new conversations + outcomes back into the next Analyze cycle.
- Roll out with confidence that you’ve already stress-tested on realistic data.
Questions?
Open an issue on GitHub or contact the maintainers. See the main README for details.
Reach us at agentune-dev@sparkbeyond.com
Try Agentune today and tell us where it takes you!


About SparkBeyond
SparkBeyond delivers AI for Always-Optimized operations. Our Always-Optimized™ platform extends Generative AI's reasoning capabilities to KPI optimization, enabling enterprises to constantly monitor performance metrics and receive AI-powered recommendations that drive measurable improvements across operations.
The Always-Optimized™ platform combines battle-tested machine learning techniques for structured data analysis with Generative AI capabilities, refined over more than a decade of enterprise deployments. Our technology enables dynamic feature engineering, automatically discovering complex patterns across disparate data sources and connecting operational metrics with contextual factors to solve the hardest challenges in customer and manufacturing operations. Since 2013, SparkBeyond has delivered over $1B in operational value for hundreds of Fortune 500 companies and partners with leading System Integrators to ensure seamless deployment across customer and manufacturing operations. Learn more at SparkBeyond.com or follow us on LinkedIn.
Related Articles
It was easier in this project since we used this outpout
Business Insights
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Predictive Models
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Micro-Segments
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Features For
External Models
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Business Automation
Rules
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Root-Cause
Analysis
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis

